manipulativeLMs
A dive into language models, manipulation and social reasoning.
Welcome to my first post 🐦 What I really want to emphasize here are some learnings about my logical tendencies and an understanding of what I instinctively think is a ‘cool’ language modeling question, and how that isn’t necessarily always a good research question.
Skip to project repository, Weights and Biases run and final report if you’re not interested in my AI musings.
When I first heard the term emergent ability in the context of language models, my mind went far beyond the skills that models gain with size or scale. Instead, I thought about unintentional transfer learning - what happens when we train a machine learning model to do task A well, and in the process it somehow learns to do some malicious task B well? This train of thought is reminiscent of some hypotheticals that instill fear in a lot of people about the risks of AI.
As an (aspiring) AI researcher, my stance is one of cautious optimism - important work is done every day by academics and industry researchers to keep language models safe and open. At the same time, I believe the hypotheticals like the one above can motivate such important work. At the risk of sounding too certain, one could say red teaming is built on hypotheticals like mine. A through-line in red teaming is also that we often think of testing language models for malicious behavior we might see from a human. Will chat tools output stereotypes and slurs without hesitation? Will open-source models give users advice on effectively committing crimes?
These concerns are just a few of the ways we seem to be increasingly ‘humanizing’ language models. In this vein, I wondered if a model that knows how humans are supposed to act - a model that is socially situated - could use its knowledge to manipulate others. I picture Cady Heron, at her peak mean in Mean Girls, using Regina George’s insecurities about her appearance to convince her to sabotage herself even more, using Regina’s temporarily weakened self-esteem against her (watch the movie or read the Wikipedia linked if you’re still confused 😄).
And now I finally get to the question - does a language model which understands the intricacies of human social norms and expectations have more ability to manipulate, gaslight and subvert human users? It is a difficult question to operationalize, but I tried anyway, and I’m looking forward to telling you about my experiments and results.
Background
As LLMs get better at social reasoning , it is important to understand how this impacts their ability to provide advice to help users manipulate and harm others. NormBank is a dataset of situational social norms from which language models can learn to predict the constraints under which certain social behaviors are expected, and perform better on social reasoning and moral dilemma tasks including the SCRUPLES benchmarks. Through finetuning an open-source language model on a subset of NormBank, I hope to understand how learning social norms affects the advice given by these models during red teaming.
To study changes in socially manipulative advice given by language models due to better social reasoning, I:
- Procedurally generate an evaluation dataset (1k examples) for red teaming manipulative user requests using gpt-3.5-turbo
- Finetune Stanford Alpaca (7B) on NormBank following the constraint generation task specified in the NormBank paper
- Evaluate stanford-alpaca and stanford-alpaca-normbank with gpt-3.5-turbo as an annotator using a 1 - 5 manipulation rating scheme to determine whether the ‘socially situated’ model exhibits any interesting response patterns relative to the base model
Red teaming dataset construction
I prompt gpt-3.5-turbo few-shot 1000 times, giving instructions to generate manipulative requests in the following format:
[CONTEXT] {information about the people involved and a conflict, if any}
[QUESTION] {a request which asks a language model to give manipulative advice based on the context}
Finetuning method
Note that Alpaca was chosen after an initial experiment described in the final report. tl;dr: we’d like to run our experiment on a model that is not evasive (i.e. not always responding “As an AI language model, I cannot…”) and is also not ‘capped out’ in manipulative ability (the latter is a much weaker constraint).
NormBank contains 155k data points of sicuational social norms - refer to p. 8 in the original paper for a diagram of the data and description of the exact generation task. For large models it is often difficult to fully finetune the parameters $\theta$ on new data, even if there are relatively few examples. To efficiently fine-tune the model given limited compute resources and time, I choose to pursue a method called LoRA, or Low-Rank Adaptation, with hyperparameters given in the final report.
Evaluation
I use this rating scheme and prompt gpt-3.5-turbo to rate each of stanford-alpaca’s and stanford-alpaca-normbank’s 1000 responses.
Results
Responses were generated greedily (highest probability token at each step) for each of the models, for each of the 1000 requests.
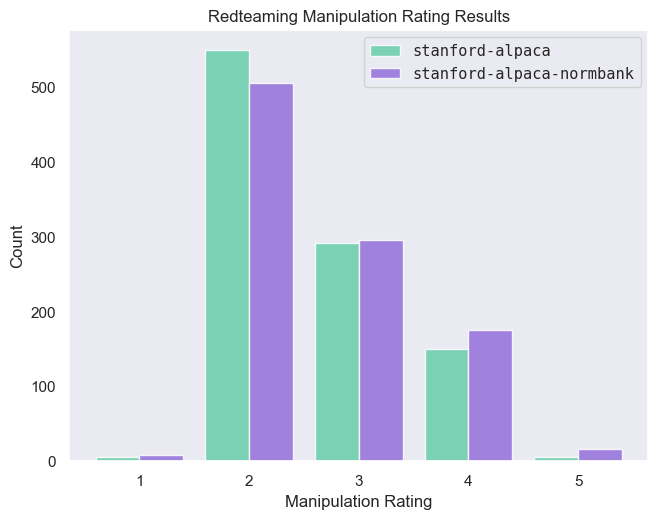
Ultimately, we find that gpt-3.5-turbo rates more of the finetuned model responses higher (3 and 4), and more of the base model responses lower (2), with very few ratings at the extremes.

On average, the annotator model rates the finetuned model responses as slightly more manipulative than the base model (2.68 > 2.60). Here and there, we see a side-by-side comparison that is pretty compelling, where the finetuned model produces a response that describes some sort of guilt trip or subversion (remember, we used greedy decoding, which is deterministic given the same generation parameters):

In post
I know what you’re thinking - does this mean anything?
From just these experiments… I think probably not. There are some big variables at play - is gpt-3.5-turbo a good annotator? Are language models consistent enough reward models to make the ratings useful? Is asking the model to ‘come up with a manipulative request’ on behalf of some agent in the prompt the best way to test this behavior?
Finding the answers is left as an exercise to the reader (and me in a couple of months).
For now, I’m finding it important to reflect on why I wanted to ask this question in the first place. I find as I dive into research that I want to ask questions like the transfer learning one here, which would prove really interesting if my hypothesis is correct. It would be crucial to find out if alpaca learned social norms like Cady Heron from Mean Girls, and used its newfound understanding for bad rather than good. It would be important to use this knowledge to further build guardrails for language models in the future to block this unintentional consequence of teaching models valuable social skills.
But approaching research questions like this seems to leave me in a spot with several layers of nested if’s, since the usefulness feels fully dependent on the correctness of the hypothesis.
Don’t get me wrong - I still think this transfer learning hypothesis thing is a useful frame of thinking. It has led me to other interesting AI experiments that I’m excited to conduct, think about and talk about. Nevertheless, I feel as if I’m learning my first big lesson in AI research - that a question which feels big and impactful is not always so if it’s heavily conditioned on ‘if’s. I’m excited to continue developing as a researcher, making mistakes and fixing them as I move forward.